카페검색 본문
카페글 본문
-
Re: 문제217. (오늘의 마지막 문제) 자동화 코드 4번에 커피 키오스크 모듈 불러오는... 2022.06.23해당카페글 미리보기
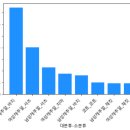
15.groupby('telecom')['ename'].count().reset_index() a.columns = ['통신사', '인원수'] a.plot(kind = 'bar', color...0) """) elif num == 4: print(""" 1. kiosk데이터를 쌓는 함수이다. (종류, 수량) from month2000 import kiosk as k k.cafe_data...
-
Re: 문제217. (오늘의 마지막 문제) 자동화 코드 4번에 커피 키오스크 모듈 불러오는... 2022.06.23해당카페글 미리보기
result.columns =['직업', '토탈월급'] from matplotlib import font_manager, rc font = font_manager.FontProperties(fname="c:/Windows/Fonts/malgun.ttf").get_name() rc('font', family=font) result.plot(kind='bar', color='green', x='직업', rot...
-
Re: 문제217. (오늘의 마지막 문제) 자동화 코드 4번에 커피 키오스크 모듈 불러오는... 2022.06.23해당카페글 미리보기
result.columns = ['부서번호','토탈월급'] from matplotlib import font_manager,rc font_path = "c:\Windows\Fonts\malgun.ttf" font_name = font_manager.FontProperties(fname = font_path).get_name() rc('font',family=font_name) result.plot(kind...
-
Re: 문제217. (오늘의 마지막 문제) 자동화 코드 4번에 커피 키오스크 모듈 불러오는... 2022.06.23해당카페글 미리보기
ename'].count().reset_index() result.columns=['통신사','인원수'] result.plot(kind='bar', color ='orange', x='통신사...bbox_to_anchor=(1,1))''') elif num == 4: print(' ') print('''from m2000 import kiosk as k 함수1: cafe_data(num1,num2...
-
파이썬 데이터 분석 관심의 급등세 지속. 그래서 데이터분석에서 무엇을 하는가 2022.05.12해당카페글 미리보기
건의 빈도 dfx['recCnt'] = 1 dfx = dfx.groupby(dfx.columns[0]).count().reset_index() # 빈도로부터 구성비 계산. 100 곱해서...return(dfx) # 대분류별 소분류의 판매건수를 사용자정의함수로 집계한 결과를 # 데이터프레임으로 저장한 후 시각화...
-
오진희 2022.03.23해당카페글 미리보기
plot을 사용한다. 이때 필요한 라이브러리는? matplotlib.pyplot 5.데이터 프레임에서 행과 열을 삭제하는 함수는? drop 데이터프레임명.drop(columns=['컬럼명'], inplace=True) 6.두 데이터프레임을 조인할 때 행과 열을 합하는 함수는? join, concat 7...
-
Re: 문제417. 위의 코드를 다르게 했거나 좀더 간추린 코드로 정리했으면 답글을 달아주세요 ~~ 2022.03.02해당카페글 미리보기
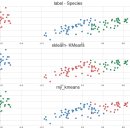
my_kmeans 함수로 군집화 my_kmeans(df_scaled,2) # 정규화한 데이터 ################################################ 3...components = 2) #2차원으로 축소 df_pca = pca.fit_transform(df_scaled) DF_PCA = pd.DataFrame(df_pca,columns...
-
Re: 문제358.(오늘의 마지막 문제) iris 데이터로 분류하는 파이썬 신경망을 생성하세요 ~~ 2022.02.22해당카페글 미리보기
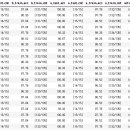
after.columns = [ 'random_state', 'a_test_acc', 'a_test_cnt', 'a_train_acc', 'a_train_cnt', params[0][0], params[1][0], params[2][0], ] result = pd.merge(before, after, on = 'random_state') # 두 결과 값을 합친 데이터 프레임 생성 개선 전...
-
Re: 문제345. (오늘의 마지막 문제) 위의 model3의 성능을 더 올리는데 활성화 함수는 relu 로 두고... 2022.02.21해당카페글 미리보기
pd.DataFrame(columns = {'h1', 'h2','corrcoef'}) for i in range(200,301, 10): for j in range(50,61): model3...hidden_layer_sizes=(i,j), #은닉 1층 200개, 은닉 2층 50개 activation='relu', #신경망의 뉴런에 들어가는 활성화함수 relu 사용...
-
Re: 문제345. (오늘의 마지막 문제) 위의 model3의 성능을 더 올리는데 활성화 함수는 relu 로 두고... 2022.02.21해당카페글 미리보기
df = pd.DataFrame(columns=['은닉층1','은닉층2','상관계수']) for i in range(100,301,100): for j in range(50,201,50): from sklearn.neural_network import MLPRegressor model3 = MLPRegressor(random_state=0, # seed 값 hidden_layer_sizes=(i, j...